










Hoy en día las empresas dependen en gran medida de la tecnología para mantener un funcionamiento fluido. Sin embargo, cuando los sistemas críticos fallan, las consecuencias suelen ser nefastas, afectando la productividad, los ingresos y la confianza de los clientes.
En este punto, la Gestión de Incidentes Mayores marca la diferencia. Porque permite manejar este tipo de problemas de modo de minimizar el tiempo de inactividad y garantizar la continuidad del negocio.
Dicha práctica no consiste únicamente en resolver los inconvenientes con rapidez, sino sobre todo en disponer de un proceso estructurado que facilite a los equipos de IT la respuesta, el manejo y la resolución de los incidentes con eficacia.
Este artículo explora el concepto de Gestión de Incidentes Mayores o Graves, los pasos que implica, las mejores prácticas y las herramientas capaces de ayudar a las organizaciones a adelantarse a posibles desastres.
Definición de Gestión de Incidentes Mayores
La Gestión de Incidentes Mayores se refiere al proceso de manejo de aquellos incidentes que interrumpen significativamente las operaciones del negocio o suponen un alto riesgo para la organización. Se trata de inconvenientes que exigen una atención inmediata y una respuesta coordinada de varios equipos para restablecer lo antes posible el servicio normal. Además, se diferencian de los normales por su gravedad y el nivel de impacto que tienen en la empresa.
En el ámbito de la Gestión de Servicios de IT (ITSM), la Gestión de Incidentes Mayores constituye un procedimiento especializado, diseñado para abordar aquellos problemas que excedan el alcance de la Gestión de Incidentes habitual.
En efecto, implica procesos, funciones y estrategias de comunicación predefinidos para garantizar una respuesta rápida y eficaz, con el objetivo principal de minimizar el impacto en la empresa y evitar que se agrave el incidente.
La Gestión de Incidentes Graves en el contexto de ITSM
En la mayoría de los marcos de ITSM, la Gestión de Incidentes Mayores ocupa un papel fundamental. Se trata de un proceso clave que las organizaciones utilizan para abordar y mitigar las interrupciones de alto impacto.
Mientras que la Gestión de Incidentes habitual se ocupa de los problemas cotidianos que surgen en los sistemas de IT, la Gestión de Incidentes Mayores se activa cuando dicho incidente alcanza un nivel de gravedad que amenaza con interrumpir significativamente las operaciones de la empresa.
Para profundizar sobre el concepto, es esencial entender primero el entorno de ITSM más amplio: es un conjunto de prácticas que garantiza la alineación de los servicios de IT con las necesidades de la empresa.
La Gestión de Incidentes Mayores encaja en este marco como un proceso especializado, que sólo se activa en circunstancias específicas. Así, sirve como red de seguridad de la organización, es decir que si algo sale mal, existe un camino claro hacia su resolución.
Para abordar eficazmente los incidentes graves, las empresas requieren un proceso bien definido, con funciones, responsabilidades y canales de comunicación claros. Este procedimiento se apoya en una serie de herramientas y tecnologías creadas para facilitar la rápida detección, respuesta y solución de dichos inconvenientes.

Lectura recomendada
Read Article
Los 5 niveles de gravedad de los incidentes -y una matriz gratuita-
Ejemplos de incidentes mayores
Los incidentes mayores pueden adoptar diversas formas, cada una con sus propios desafíos e impactos. He aquí algunos ejemplos comunes:
- Cortes de la red: puede detener las operaciones de toda una organización porque sin conectividad, los empleados no acceden a los sistemas esenciales, lo cual provoca una interrupción de la productividad y pérdidas financieras potencialmente significativas.
- Fallos del servidor: paraliza la capacidad de una empresa para prestar servicios, sobre todo si allí se alojan las aplicaciones críticas. Como consecuencia, genera tiempos de inactividad, pérdida de los datos y experiencia negativa del cliente.
- Filtraciones de los datos: los incidentes de seguridad como las violaciones de la información suelen tener efectos de gran alcance, como la pérdida de los datos sensibles, sanciones reglamentarias y daños a la reputación de la organización. Por lo tanto, requiere una acción inmediata para mitigar la brecha y evitar problemas mayores.
- Tiempo de inactividad del servicio en entornos en la nube: un ejemplo reciente es la interrupción de CrowdStrike, que afectó a varios clientes y puso de relieve la importancia de contar con procesos sólidos de Gestión de Incidentes Mayores en este tipo de espacios.
- Catástrofes naturales que impactan en la infraestructura de IT: terremotos, inundaciones o incendios pueden dañar físicamente el portfolio tecnológico, provocando incidentes graves que demandan respuestas rápidas y eficaces para restaurar los servicios y proteger los datos.
Pasos del proceso para gestionar incidentes graves
La Gestión de Incidentes Mayores implica varios pasos críticos que forman parte de un enfoque estructurado para asegurar que se resuelvan de forma rápida y eficaz. Se trata de una guía para los equipos de IT, que involucra desde la detección inicial hasta la resolución y la revisión posterior.
Aquí, las fases del proceso:
Paso 1: Detección y clasificación
El procedimiento comienza con la detección y clasificación del incidente, es decir, la identificación del problema y la determinación si puede considerarse grave. Las herramientas de monitoreo automatizado y las alertas desempeñan un papel crucial en su descubrimiento temprano, de manera de poder responder con celeridad.
Una vez detectado, el incidente debe clasificarse en función de su gravedad e impacto, ya que ayuda a priorizar la respuesta y garantiza que se asignen los recursos adecuados para su gestión.
Para ello, hay que establecer criterios claros, teniendo en cuenta factores como el número de usuarios afectados, el efecto financiero potencial y la criticidad de los sistemas implicados.
Paso 2: Escalamiento
Una vez que el incidente se clasifica como grave, tiene que escalarse a los equipos adecuados para su resolución, a la vez de informar la situación a los responsables de la toma de decisiones.
Una ruta de escalamiento predefinida debe guiar el proceso, garantizando que todas las partes involucradas participen rápidamente.
Durante el escalamiento, la comunicación es clave. Por lo tanto, hay que proporcionar actualizaciones claras y concisas a todos los afectados, incluyendo los equipos de IT, la dirección y los usuarios. Esto ayuda a gestionar sus expectativas y los mantiene al tanto de los progresos.
Paso 3: Respuesta y contención
Con el objetivo de evitar que el incidente cause más daños y estabilizar la situación, el siguiente paso es iniciar los esfuerzos de respuesta y contención, lo cual puede implicar aislar los sistemas afectados, redirigir el tráfico o cerrar temporalmente determinados servicios.
Los equipos de respuesta seguirán procedimientos y guías predefinidos para asegurar una respuesta coordinada y eficaz. La colaboración entre diferentes áreas, como redes, servidores y seguridad, resulta esencial durante esta fase. Para ello, permanecerán abiertos los canales de comunicación, con actualizaciones periódicas a las partes interesadas sobre el estado de los esfuerzos de contención.
Paso 4: Resolución
Tras la contención del incidente, la atención pasa a centrarse en la resolución del problema y el restablecimiento de las operaciones normales. Este paso contempla la identificación de la causa raíz y la aplicación de las correcciones necesarias para evitar que se repita. Dependiendo de su naturaleza, pueden ser parches de software, sustituciones de hardware o cambios en la configuración del sistema.
Los esfuerzos de resolución tienen que documentarse minuciosamente, con un registro claro de los pasos dados para solucionar el inconveniente. Dicha información será valiosa para la revisión posterior así como para la prevención de incidentes similares en el futuro.
Paso 5: Revisión posterior
El último paso del proceso es la revisión posterior al incidente, que consiste en su análisis para comprender qué salió mal, qué se hizo bien y qué puede mejorarse en el futuro. Dicho estudio debe llevarse a cabo con todas las partes interesadas y dar lugar a un reporte detallado en el que se exponen las conclusiones y recomendaciones.
Esta instancia representa una oportunidad para reforzar los procesos de la Gestión de Incidentes de la organización y de aprender sobre el mismo. También brinda la oportunidad de actualizar las guías de actuación, perfeccionar los criterios de clasificación y optimizar las estrategias de comunicación para futuras situaciones similares.
10 mejores prácticas para manejar incidentes mayores
Para que la Gestión de Incidentes Mayores resulte eficaz no basta con seguir una serie de pasos, sino que también hay que atenerse a las mejores prácticas que ayudan a garantizar un resultado satisfactorio.
He aquí cuestiones a tener en cuenta:
1. Crear un equipo específico para la Gestión de Incidentes
Para la Gestión de Incidentes Mayores es clave contar con un equipo específico formado por profesionales experimentados y capacitados para manejar situaciones de alta presión.
El grupo debe estar familiarizado con los sistemas, los procesos y los canales de comunicación de la organización, a la vez de contar con las facultades para tomar decisiones críticas durante un incidente.
2. Desarrollar y mantener manuales de los incidentes
Los manuales de los incidentes proporcionan una guía paso a paso para gestionar distintos tipos de problemas graves y garantizar que la respuesta sea coherente y eficaz. Este material tiene que desarrollarse basándose en situaciones pasadas y escenarios potenciales. Además, requiere actualizaciones periódicas para reflejar los cambios en el entorno de IT de la organización.
3. Implementar el monitoreo y las alertas automatizadas
Las herramientas de monitoreo automatizado resultan esenciales para la detección temprana de los incidentes, ya que supervisan continuamente los sistemas de la organización y activan alertas cuando se detecta un problema.
El monitoreo automatizado permite reducir el tiempo que se demora en identificar y responder a los incidentes graves.
4. Realizar simulacros periódicos de los incidentes
Los simulacros periódicos de los incidentes ayudan a preparar al equipo para situaciones reales, ya que ponen a prueba la capacidad de respuesta de la organización.
Así, mediante la realización de simulacros, es posible identificar puntos débiles en los procesos y realizar mejoras antes de que se produzca un incidente real.
5. Garantizar canales claros de comunicación
Una comunicación clara es fundamental durante un incidente grave. Todas las partes interesadas, incluidos los equipos de IT, la dirección y los usuarios afectados, deben mantenerse informados durante todo el incidente.
El establecimiento de canales de comunicación específicos, como salas de chat o espacios de conferencia para los incidentes, facilitan las actualizaciones y la coordinación en tiempo real.
6. Priorizar la clasificación y la reducción de la intensidad de los incidentes
Teniendo en cuenta que no todos los incidentes demandan el mismo nivel de respuesta, la clasificación y escalamiento de los incidentes garantiza que los más críticos reciban atención prioritaria.
Para ello, hay que establecer criterios claros de clasificación y escalamiento de modo de evitar que los incidentes menores sean abordados de la misma manera que los graves, y destinar los recursos para estos últimos.
7. Documentar las acciones de respuesta a los incidentes
Todas las acciones emprendidas durante un incidente se documentan minuciosamente, porque sirve como registro de aquello que se hizo, quién participó y cuáles fueron los resultados.
También es valiosa para la revisión posterior al incidente y para perfeccionar los procesos de Gestión de Incidentes de la organización.
8. Llevar a cabo el Análisis de la Causas Raíz
Para evitar que vuelva a ocurrir el incidente, es fundamental comprender la razón de su origen. Así, un Análisis de la Causa Raíz (RCA - Root Cause Analysis) ayuda a identificar los problemas subyacentes que condujeron al incidente y proporcionar ideas sobre cómo evitarlos en el futuro.
9. Focalizar en la mejora continua
La Gestión de Incidentes Mayores va más allá del esfuerzo puntual, ya que requiere una mejora continua.
La revisión periódica de los procesos, la incorporación de las lecciones aprendidas sobre los incidentes anteriores, la actualización de los procedimientos y las guías forman parte de esta tarea.
En ese contexto, las organizaciones tienen que fomentar una cultura de aprendizaje permanente en la cual la retroalimentación de cada incidente se utilice para optimizar las respuestas futuras.
10. Aprovechar las herramientas de Gestión de Incidentes
La utilización de un software especializado de Gestión de Incidentes puede mejorar enormemente la capacidad de una organización para manejar aquellos problemas graves.
Estas herramientas ofrecen funciones como el monitoreo en tiempo real, flujos de trabajo automatizados y plataformas de colaboración que agilizan el proceso.
Los instrumentos adecuados marcan una diferencia significativa en la eficacia de tus esfuerzos de respuesta a los incidentes.
¿Qué buscar en un software de Gestión de Incidentes Mayores?
La selección de un software adecuado para la Gestión de Incidentes Mayores es fundamental para el éxito de tus esfuerzos de respuesta, ya que permiten agilizar los procesos, mejorar la comunicación y garantizar un manejo eficaz.
Estas son algunas de las características clave que debes buscar en una solución de este tipo:
1. Monitoreo y alertas en tiempo real
La supervisión en tiempo real ayuda a tu equipo a detectar los problemas en cuanto se producen. Por lo tanto, el software en cuestión debe proporcionar alertas que notifiquen sobre posibles incidentes para poder dar una respuesta rápida.
2. Flujos de trabajo automatizados
Los flujos de trabajo automatizados garantizan que los incidentes se gestionan de forma coherente y eficaz. La solución elegida, entonces, tiene que ofrecer la posibilidad de crear dichos flujos predefinidos que guíen a tu equipo a través del proceso de Gestión de Incidentes.
3. Herramientas de colaboración
Considerando que la comunicación y la colaboración efectiva resultan fundamentales durante un incidente grave, es clave que la plataforma cuente con herramientas como chat, videoconferencia y uso compartido de archivos para facilitar la cooperación en tiempo real entre los miembros del equipo.
4. Reportes y análisis de los incidentes
Como los reportes y análisis detallados de los incidentes resultan esenciales para comprender el impacto y para realizar revisiones posteriores, es indispensable que el software disponga de funciones completas de elaboración de informes que permitan profundizar y realizar un seguimiento de las métricas importantes.
5. Integración con las herramientas de ITSM existentes
Otro aspecto a considerar es la posibilidad de integración con tus herramientas de ITSM existentes para obtener un proceso de Gestión de Incidentes sin fisuras. Por lo tanto, el software debe ser capaz de anexarse a la infraestructura de IT actual, de modo de compartir fácilmente los datos y la comunicación entre los diferentes sistemas.
Spoiler alert: en los próximos párrafos te presentamos a InvGate Service Management, nuestra propia solución de ITSM con capacidades de Gestión de Incidentes.
5 herramientas para gestión incidentes mayores
Para la Gestión de Incidentes Mayores, las herramientas tecnológicas facilitan mucho el camino. Aquí, cinco que pueden ayudarte en la tarea:
1. InvGate Service Management
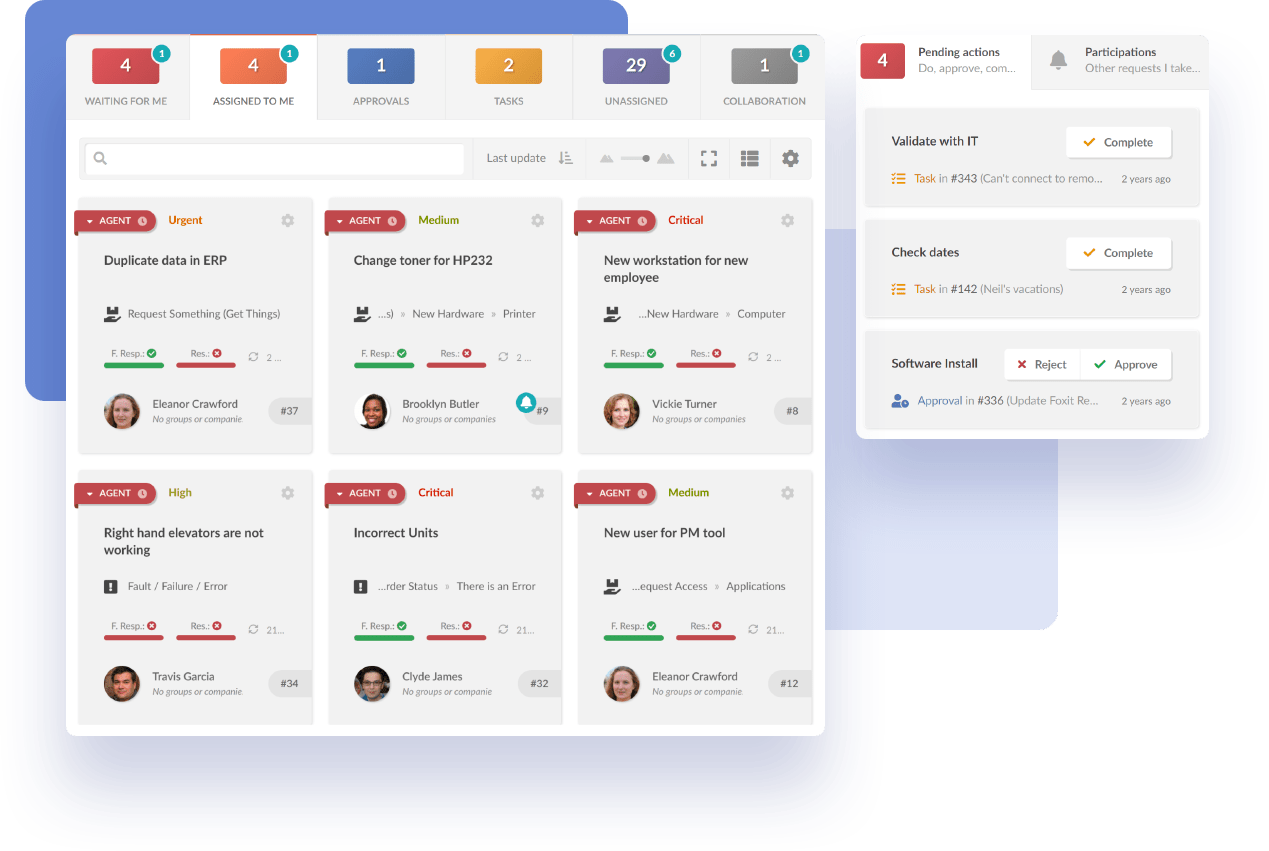
InvGate Service Management constituye una poderosa herramienta de ITSM que brinda una solución integral para agilizar el proceso de Gestión de Incidentes, incluyendo el monitoreo en tiempo real, los flujos de trabajo automatizados y las sólidas capacidades de generación de reportes.
En efecto, puedes crear flujos que guíen a tu equipo a través del proceso de Gestión de Incidentes, lo cual garantiza un manejo consistente y eficiente, reduce el riesgo de errores y mejora los tiempos de respuesta.
Además, para que la experiencia sea mucho más accesible, rediseñamos el editor de flujos de trabajo sin código, es decir, mantuvimos todas las funciones, pero simplificamos la UX/UI, redujimos la curva de aprendizaje y agregamos algunos procesos pre-construidos para que no tengas que empezar de cero.
Como mencionamos, InvGate Service Management proporciona reportes detallados de incidentes y tableros, lo cual permite realizar un seguimiento de las métricas clave y obtener información sobre el impacto de un incidente. Se trata de una herramienta valiosa para realizar las revisiones posteriores y para optimizar los procesos de Gestión de Incidentes.
2. ServiceNow
Con sólidas funciones para gestionar incidentes importantes, ServiceNow es una popular herramienta de ITSM que cuenta con monitoreo en tiempo real, flujos de trabajo automatizados y potentes análisis para ayudar a las organizaciones a gestionar eficazmente sus esfuerzos de respuesta.
3. PagerDuty
Por su parte, PagerDuty representa una plataforma de Gestión de Incidentes que se centra en alertar y responder en tiempo real. Además, se integra con varias herramientas de monitoreo para consolidarse como una solución integral para el manejo de inconvenientes graves.
4. Opsgenie
Otra herramienta de Gestión de Incidentes es Opsgenie, que ofrece funciones de alerta, garantizando que se notifique a las personas adecuadas en el momento oportuno. Esto ayuda a los equipos a poder responder con celeridad.
5. Jira Service Management
Con potentes funciones de Gestión de Incidentes, Jira Service Management es una herramienta de ITSM que incluye monitoreo en tiempo real, flujos de trabajo automatizados y capacidades completas de generación de reportes.
Reflexiones finales
La Gestión de Incidentes Mayores constituye un aspecto crítico de las operaciones de IT. La implementación de este proceso requiere aplicar las mejores prácticas y aprovechar las herramientas adecuadas para minimizar el impacto y garantizar la continuidad del negocio.
A medida que los entornos tecnológicos sigan evolucionando, la capacidad de manejar incidentes graves con eficacia será cada vez más importante. Tanto si estás empezando a crear tu proceso como si deseas perfeccionar el enfoque actual, las estrategias y plataformas que se describen en este artículo te ayudarán a estar preparado y contar con la capacidad de respuesta necesaria.
Preguntas frecuentes
1. ¿Qué es la Gestión de Incidentes Mayores?
La Gestión de Incidentes Mayores se refiere al proceso de manejar estos incidentes que interrumpen significativamente las operaciones empresariales o suponen un alto riesgo para la organización. Implica un procedimiento estructurado para garantizar una respuesta rápida y eficaz con el fin de minimizar el impacto y restablecer el servicio normal.
2. ¿Qué ejemplos existen de incidentes graves?
Entre los ejemplos de incidentes graves se incluyen las interrupciones de la red, los fallos de los servidores, las violaciones de los datos, el tiempo de inactividad del servicio en entornos en la nube y los desastres naturales que afectan a la infraestructura de IT.
3. ¿Cuáles son los pasos clave en un proceso de Gestión de Incidentes Mayores?
Los pasos clave contemplan la detección y clasificación de los incidentes, su escalamiento, respuesta y contención, resolución y revisión posterior.
4. ¿Cuáles son las mejores prácticas para la Gestión de Incidentes Mayores?
Las mejores prácticas son el establecimiento de un equipo específico, el desarrollo y el mantenimiento de manuales de los incidentes, la implementación del monitoreo y las alertas automatizadas, la realización periódica de simulacros y el establecimiento de canales de comunicación claros.
5. ¿Qué características debo buscar en un software de este tipo?
Entre las características fundamentales que debes buscar se incluyen la supervisión y las alertas en tiempo real, los flujos de trabajo automatizados, las herramientas de colaboración, los informes y análisis de los incidentes y la integración con las herramientas de ITSM existentes.
Descargo de responsabilidad: Todos los nombres de productos, logotipos y marcas son propiedad de sus respectivos dueños. Todos los nombres de empresas, productos y servicios utilizados en este sitio son solo para fines de identificación. El uso de estos nombres, marcas registradas y marcas no implica ningún tipo de respaldo. Las comparaciones se basan en información disponible públicamente y se proporcionan únicamente con fines informativos. ServiceNow es una marca registrada de ServiceNow, Inc. InvGate no está afiliada, patrocinada ni respaldada por ServiceNow.

