









Google has introduced so many innovations that it’d be impossible to list them all. And we’re not just talking about the obvious things like search engine algorithms or nearly-ubiquitous programs and apps (Google Maps, Docs, Gmail) — not even self-driving cars. Today, we’re going to talk about one such innovation: Site Reliability Engineering.
In a nutshell, SRE it’s a practical framework for software development that improves on even giants like DevOps. Wait, what? Yeah, if you’ve been struggling to implement DevOps in your organization, you may be falling over yourself thinking that there’s an even bigger and badder player in town.
Hold your horses, though! SRE does bring a lot to the table that DevOps lacks, but it’s actually its own thing and they’re both not mutually exclusive. SRE encourages growth and cooperation between Development and Operations, two oft-embattled parts of the software development pipeline.
With things like product reliability, innovation, and increased levels of accountability, it ups the ante and fosters a more grown-up version of the IT workspace — one where different departments aren’t having cage matches 24/7.
So, first, let’s take a look at how it accomplishes this exactly.
What is Site Reliability Engineering (SRE)?
SRE was first introduced in 2003 by Google SRE engineer Ben Treynor Sloss. If you may grant us the poetic license, we could picture him as the site reliability engineering’s founding father. When Google gave him the objective of creating more integrated teams, he came up with the term, as well as a whole new set of operational principles.
According to Treynor Sloss, SRE is “what happens when a software engineer is tasked with what used to be called operations.”
Now, SRE tries to fix what is usually a very common problem in organizations: siloing. Meaning, that teams work irrespective of each other in their own compartmentalized little areas, unaware of what the other is doing.
Usually, development teams want to release some necessary new features to the public and hit the ground running. But the operations team can and must make sure that those bangin’ new features don’t make the whole software structure come crashing down like a house of cards.
You can probably imagine how this often leads to some pretty Shakespearean power struggles. And the unintended consequence is a bit of a tug-of-war, with Ops playing the mean dad, and Devs looking for a window to climb down so they can avoid the “totally unfair” curfew.
Site reliability engineering removes all of this pesky debate in one fell swoop. No more bickering about what can be launched and when. To do this, SRE algorithmically greenlights (or red lights, we guess) projects according to pre-established criteria.
But who are the dedicated professionals that oversee this magic? Let’s take a quick look at the role of the SRE engineer.
What does an SRE engineer do?
A Site Reliability Engineer’s main job is to make sure that a product is stable, reliable, and easy to iterate upon. So, as you can imagine, they have to be proficient at more than just coding. Alongside that, they need to have operations experience, so they have to be people-person as well. SysAdmins – or IT operations roles that also have development experience – can also pass muster.
SRE teams are responsible for a lot of what happens to services in production:
- Deploying, configuring, and monitoring code
- Availability response
- Latency
- Change management
- Emergency response
- Capacity management
In short, SRE can help teams determine what’s launch-ready and what isn’t by using SLAs (Service-Level Agreements) to pre-define the required reliability of the system. In turn, engineers achieve this through SLIs (Service-Level Indicators) and SLOs (Service-Level Objectives).
But this also happens through a sort of “hierarchy of needs.” It’s time to take a look at the SRE pyramid.
SRE principles: the Site Reliability Engineering pyramid
The processes or systems that SREs run are solely their responsibility. This means that they have to carefully manage the health of these services. But it’s no easy task to do this successfully. Monitoring systems, incident response, planning capacity, and getting to the bottom of service outages, etc., can be time-consuming and require expert hands and eyes.
Site reliability engineering, as a daily practice, entails building complex distributed systems from the ground up, and then running them efficiently.
So, what does a “healthy” or well-run service look like? It’s a bit like the Maslow Hierarchy of Needs:
“Maslow's hierarchy of needs is a motivational theory in psychology comprising a five-tier model of human needs, often depicted as hierarchical levels within a pyramid.
From the bottom of the hierarchy upwards, the needs are: physiological (food and clothing), safety (job security), love and belonging needs (friendship), esteem, and self-actualization.
Needs lower down in the hierarchy must be satisfied before individuals can attend to needs higher up.”
And this is how the SRE pyramid functions precisely: by determining which services are necessary (and thus lower in the pyramid), and which ones depend on those needs being met.
So, what comes first, and what comes after in the site reliability engineering pyramid of needs? Let’s take a look.
1. Monitoring
Monitoring is your way to assess whether a service is doing what it’s meant to be doing. Without it, you’re just taking things in good faith and willfully waiting until something catches fire. Even more so, you want to be proactive rather than reactive; noticing your problems before your users do is part of your long-term survival strategy.
2. Incident response
We talk a lot about 24/7 support, but that’s a bit of a hyperbolic statement. Rather, on-call support is a tool that needs to be deployed carefully and judiciously. The idea is to stay in touch with how distributed IT systems work (or don’t work). Truth is, no one wants to be connected year-round, but that’s the way the cookie crumbles, and part of the engineering life because stuff breaks down all the time.
But being aware of a problem is only the first, easiest part. Then comes the moment of trying to find solutions that stick (and don’t break anything else downstream). Some solutions are temporary, and others are more elegant fixes, but you can bet that SRE engineers will be using both to stop the bleeding when something really bad happens. Incident response is something that all teams need to do and do well.
So, after identifying what the problem is, we can move on to the next step.
3. Troubleshooting
Ideally, you want solutions that you can use long-term, and that don’t cause more harm than good. When it comes to emergency response, that goes double, because today’s fix may be tomorrow’s catastrophe. And those can break the piggy bank when it comes to it.
The more your team can deploy effective incident management to deal with emerging issues, the bigger your chances for overall success. Plus, that tends to put a limit on anxiety too.
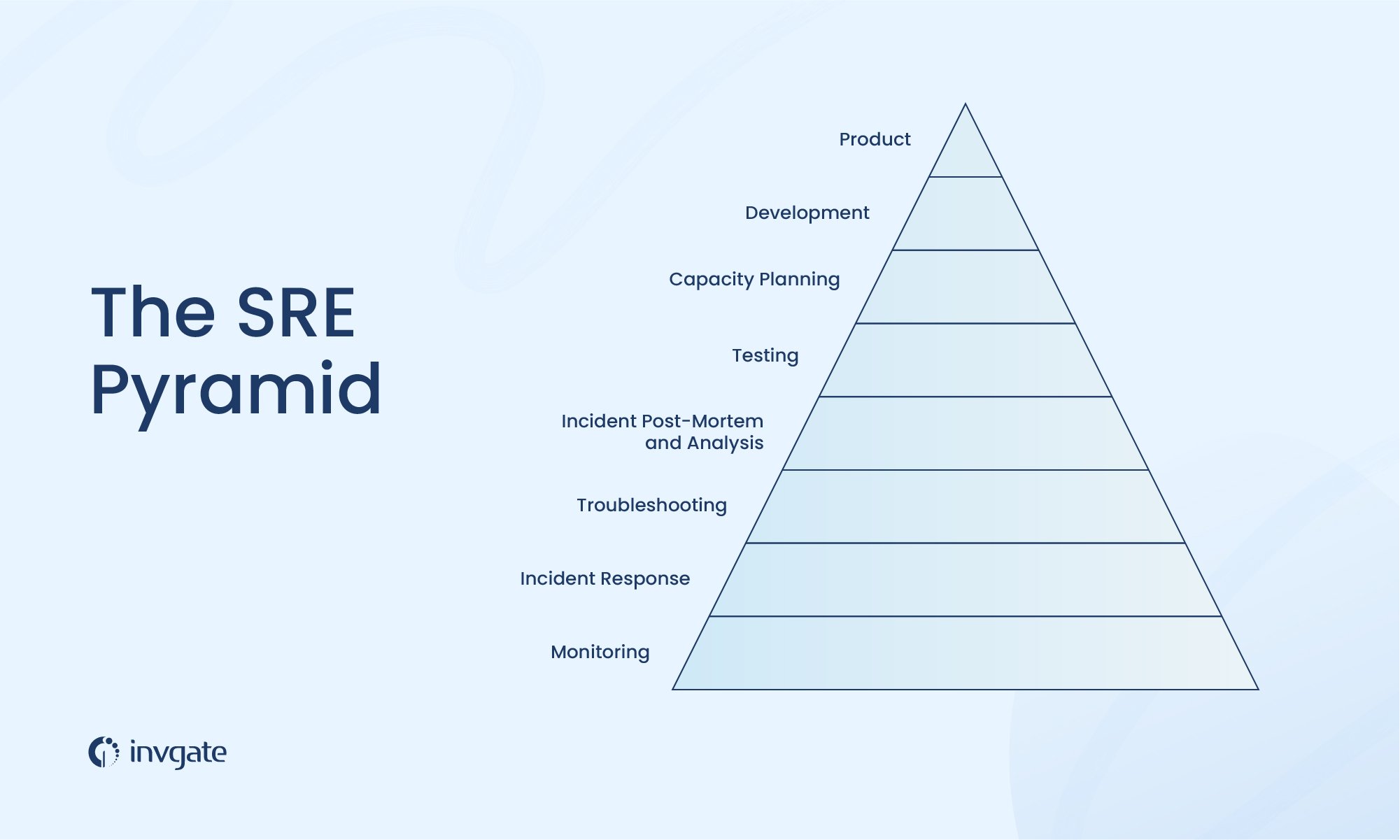
4. Incident post-mortem and analysis
Now, it’s time to get to the bottom of things and find out what actually led to all this mess. If not, then you get stuck on your own Groundhog Day loop of the same issue repeating itself over and over. And even if that causes your team to get exponentially better at solving it, it doesn’t negate the fact that they’re endlessly going around in circles.
And this is an integral part of the SRE culture: to create a blameless post-mortem culture where you can examine what went wrong and work on fixing the root causes before they pop up again like bad jump-scares in a horror movie.
In short, you and your team will have to learn from failure. And this is prime real estate for automation tools and trackers as well. Just sayin’.
5. Testing
Testing comes once we’ve understood where the holes in the hull are. Now, the idea is to prevent those holes from appearing in the first place. Prevention is going to be a much safer (not to mention cost-effective) alternative than tending to things after the fact.
This is where test suites can be a huge assistance. They can test your software thoroughly to check it for certain classes of errors before you turn it over to production. Thus, testing ensures that this software is reliable before it sees the light of day.
6. Capacity planning
The goal of capacity planning (also known as capacity management under ITIL) is to make sure that IT resources are enough to meet upcoming business requirements cost-effectively.
This is where you’ll go over every nook and cranny of your project to make sure that you’re meeting your goals in a tight, effective, and efficient manner that makes use of your existing monetary resources and budget allocations.
7. Development
At Google, it’s very frequent to see their approach to site reliability engineering take the form of plenty of in-house system design and software engineering.
This is done through a form of distributed consensus, which increases reliability. In plain English, a consensus is achieved in a non-centralized manner by being distributed alongside data nodes. This helps outline a system that is able to scale beyond whole data centers, something easier said than done.
Additionally, developers can handle about 5% of the operations workload. This happens when there’s an overflow in operations, leading devs to handle the rest. This also leads to more connection with the product in a state of real-world performance.
8. Product
This is the stage where you —hopefully— have a product that’s ready for action. The idea with SRE is to be able to provide your clients with a product that works as intended from the get-go, and not a launch-day disaster that needs to be patched into oblivion until it’s half-functional. You can say “that’d never happen to us,” but part of the reason why SRE exists in the first place is that very few companies can ensure reliable products at launch — or beyond.
Why do you need SRE?
Site reliability engineers, if we had to sum up their importance, are there to make sure that fast software development and delivery don’t lead to sub-standard software on release. But, they’re also responsible for maintaining systems and observability while leveraging automation to make these systems increasingly efficient.
Often, this also means being first-responders when something goes wrong. But this doesn’t mean they do it in isolation from others, but rather in tandem with (and within) individual teams.
Another important point of SREs is their role in making software more resilient. And this is not something you can outsource, but rather a feature that has to be designed, and built into systems. The result of these practices is that when something does go wrong, it doesn’t cascade down into the whole system and it’s much easier to limit the damage.
5 SRE best practices
If you’re planning on implementing software reliability engineering in your company, here are some of the SRE best practices you need to follow:
- Create error budgets – Meaning, the maximum amount of errors you can accumulate in your system before your users notice that something is wrong. And things being wrong makes them unhappy, which is something you don’t want.
- Think like a user to define SLOs – By doing so, you’ll measure availability and performance by thinking like a user, and not necessarily from the perspective of a developer.
- Monitoring errors and availability – Monitoring is necessary to ensure that your software is working the way it’s supposed to. Moreover, you’ll know of any changes or issues before your clients do, and that’s crucial.
- Make sure you don’t overlook change management – Changes can impact your whole system, and most outages actually happen when introducing live change. So, make sure to properly assess the most likely impact a change can have before introducing it. If the cost/benefit ratio checks out, you’re good. But always make sure you see the big picture.
- Create a blameless post-mortem culture – SNAFUs will happen, but always make sure you think positively about the people involved. Everyone’s working to the best of their capacity, and they’re not trying to make accidents happen on purpose. If you have a solid incident resolution and retrospective in place, you can make the most out of failures. And you don’t have to point fingers in order to make that happen.
5 challenges of SRE
We’ve covered the benefits and the best practices, and now it’s time to take a quick look at five challenges of SRE that can come across your path.
- There’s not enough cross-team buy-in – Maybe you’ve put together a great SRE team, but you don’t have enough site reliability engineers to ensure buy-in across teams. This can be an issue if you’ve got a large organization, so it’s up to you to keep communication streams going.
- Your process is too big to fit your incident response time – If your process is too draconian and cumbersome, it could slow down incident response times. Incident response should be as simple as possible, so you should work to whittle down those wikis and checklists to a minimum.
- You don’t learn from post-mortems – We’ve mentioned above how you can learn a lot from these types of meetings. If you don’t, then you’re asking for the same issue to repeat itself over and over and over.
- Incidents happen, and then you act – It’s important to be proactive and not wait for errors or outages to occur before you have a system in place to deal with them. Running simulations allow your engineers to be more ready when actual things happen, and they’ll thank you for it (and you’ll thank them back).
- Incident management without SLOs just won’t do – While you can have a huge amount of success implementing SRE, SLOs are an essential building block, not a bonus. This means setting an error budget, and basically, an acceptable level at which your services should run. Set realistic, trackable, clear SLOs and you’ll get the best out of SRE.
Summing up
Site reliability engineering may seem like just another new buzzword in a long line of soon-to-be-forgotten tech terms. But it’s actually a perfect solution for many of your development and operations problems.
We recommend you look into it, and start filling your teams with competent SREs who can help you reach your goals in style — and, more importantly, post-launch stability, support, and reliability.
Frequently Asked Questions
What does SRE stand for?
SRE stands for Site Reliability Engineering, a cross-team set of practices to make software development less siloed and more efficient.
What does an SRE do?
A Site Reliability Engineer is tasked with continuously making sure that a product is reliable. They also have to mitigate and prevent issues and help development and operation teams stay on the same page.
What is the goal of a Site Reliability Engineering team?
They prioritize reliability objectives by using Service Level Objectives (SLOs) to measure system or site performance.
What's the difference between DevOps and SRE?
They’re both fundamentally synergistic approaches. Their main difference between DevOps and SRE could be that SRE is a prescriptive set of practices, while DevOps is a general framework.

