










Continual service delivery is key to a great customer experience and to building a good reputation. Service interruptions - besides affecting the customer experience - can be costly to the business. In a 2025 survey, 25% of respondents said that the hourly cost of a server outage for them was somewhere between $301,000 and $400,000. Besides this, failure of critical systems can bring businesses to a halt and can even cost lives.
Designing system for high availability and developing disaster recovery plans are how businesses avoid and prepare for such situations. While both may look the same at a glance, there are many differences between the two, starting from why they’re designed to how they’re implemented.
Let’s have a look.
What does high availability mean?
Availability management is a process used to ensure that the customer or end-user can avail of the services without interruptions or disturbances as described in the service level agreement. Ensuring high availability means understanding the underlying components of a service, the risks that they face, and building the services with enough redundancies that failure of a few components doesn’t bring the service down.
Availability can significantly affect business goals or revenue streams. Poor availability of services can affect the customer experience and business reputation and you may lose your business to the competition.
In some cases, the unavailability of critical systems can cause a chain reaction with disastrous consequences. For example, if a hospital management software becomes unavailable, patient records may become inaccessible, tests and procedures may be delayed, and patient care will be affected.
Building a system for high availability is about eliminating single points of failure. Service shouldn’t become unavailable because a server went down or the power went down in a data center (read about the cost of downtime). It’s about proactively understanding the potential causes for failure and having systems in place so that the clients can still access the services even in case of these events.
Besides events that cannot be completely predicted, such as hardware failure or a cyberattack, high availability also means carefully planning predictable events, such as a software update or a security patch. Maintenance activities can potentially interrupt service delivery. In this way, availability management works with change management.
Ensuring high availability is a risk management exercise. The level of redundancies built into a system depends on the risks associated with it; how necessary is the system for the business processes?
What does disaster recovery mean?
While high availability acts as a preventative method, disaster recovery acts as the solution to the worst case scenario.
Disaster recovery is a process that is designed to bring critical services back online after a sudden or unforeseen event interrupted them. It could be a natural disaster or a fire that destroyed a data center or it could be an intern accidentally deleting an entire database. Either way, the disaster recovery process is used to bring back the business processes back to their initial state before the disaster.
While the disaster recovery plan will be triggered only in the event of a disaster, the process itself starts way before any disaster. For starters, you need to have planned the disaster recovery process way before. You need to have an updated list of assets and services that has to be recovered in the order of importance.
And you need to make sure all of your critical systems have backups. For example, to prepare for any event that takes down your servers, you need to have your data backed up in a geographically different location.
Disaster recovery plans tend to be costly, and the benefits may not always be apparent. For example, a business may keep duplicates of all of its applications or data in separate locations for 10 years. And they may not ever be needed. But if one day the business is hit with a disaster, they can go forward without much interruptions in the business processes.
The cost of the disaster recovery plan can be prohibitive if multiple redundancies are built into all the components. Therefore disaster recovery measures often focus on the absolute necessities to keep the business going: is a component absolutely necessary? How long can the business go without a certain component?
How are high availability and disaster recovery different?
The thought process behind high availability is that of preventative measures. The goal is to build services with minimum downtimes. Systems are designed to be resistant to failures, to ensure that the failure of one or more components doesn’t bring down the system.
When high availability is the prevention, disaster recovery is considered to be the cure. Disaster recovery is implemented when the system has already failed. Of course this means the measures to bring back the systems online is already built-in and the recovery plan is made before any disaster strikes. But when the disaster recovery plan is designed, the assumption is that critical systems have failed, and the goal is to make these services and business processes back online.
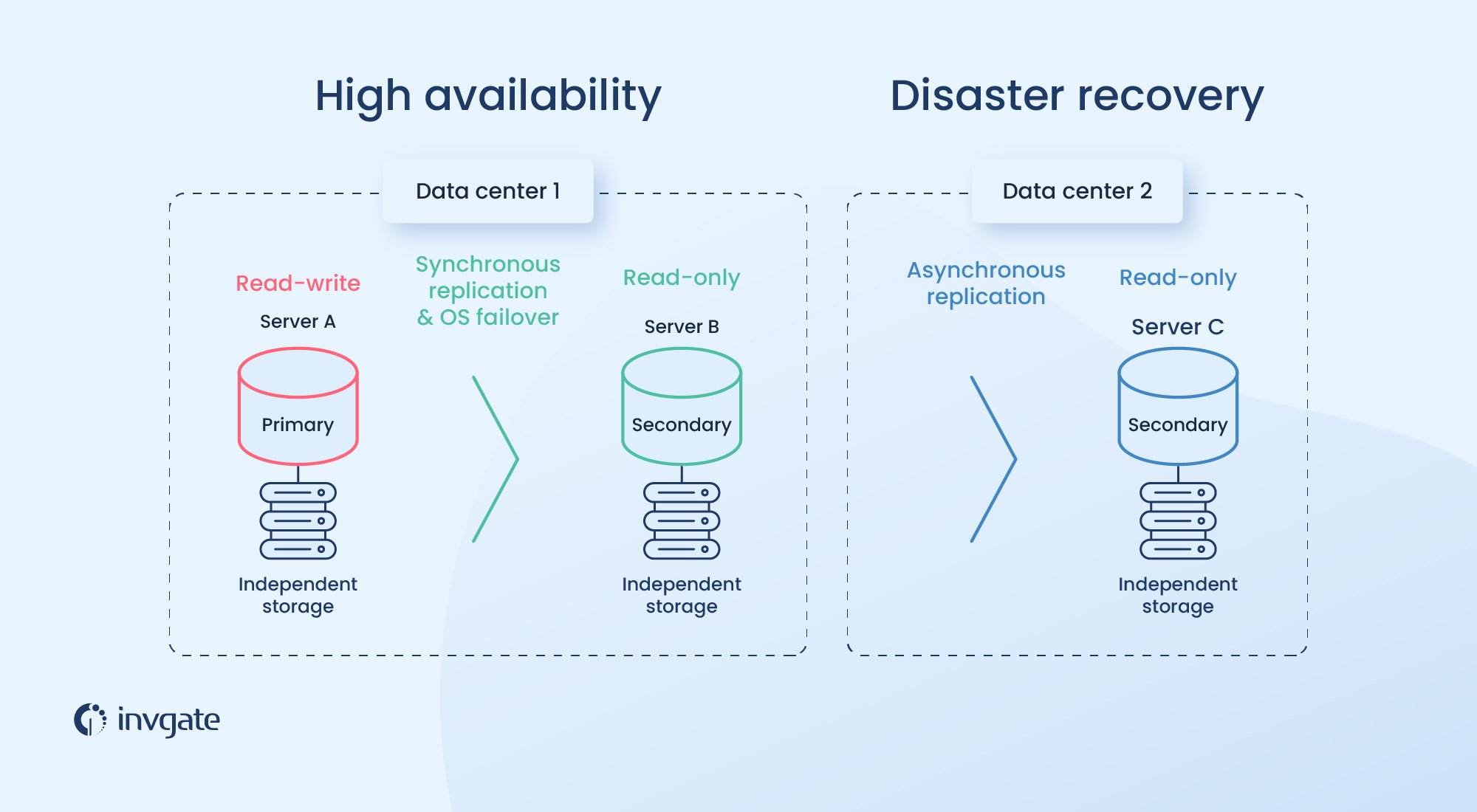
Another difference is that in ensuring high availability there’s a high focus on individual systems; the redundancies are built in on all the systems that have a high availability requirement. In very simple terms, this is a fair-weather design; everything is going perfectly well, but in case one or two systems go down, there are systems to back them up. And you have all the resources to keep these services uninterrupted without having to prioritize.
But with disaster recovery, all or most systems are affected. And you may not have the resources to bring them all back up at the same time and you may have to prioritize which systems need to be back up fast and which can afford to be down for a while.
Another difference is the standards or SLA metrics used to track high availability and disaster recovery. For availability, this is measured in MTRS or mean time to restore services, and MTBF or mean time between failures. MTRS refers to how quickly the organization can restore services after a failure and MTBF refers to how often a service becomes unavailable.
In disaster recovery, two factors that come into the design are RTO or recovery time objective and RPO or recovery point objective. Recovery time objective is similar to MTRS and refers to how long it is acceptable for business processes to be down.
The recovery point objective or RPO refers to the point from which the system must be restored. For example, if you design a system that performs backups every twelve hours, and a failure occurs right before the backup, all the data you’ve collected or all the changes you’ve made in the past twelve hours will be lost. You can restore the system back to the state it was in 12 hours ago. So the recovery point objective, in this case, would be 12 hours.
Another difference is how high-availability and disaster recovery systems are designed. With high availability, since the goal is to prevent downtime, the systems are designed so that in case one fails, the other one takes over without delay or any loss. For example, two servers may carry out the same processes at the same, so that even if one fails, the other server has exactly the same process going on and can take over almost seamlessly.
But what happens if both of these servers go down due to some underlying reasons? This is where disaster recovery kicks in. In this case, the backup servers won’t have the exact same processes going on and may not take over seamlessly. This is by design; the same problem that took down the other servers shouldn’t have taken down this server as well. Which is why they are often at different geographical locations.
How do high availability and disaster recovery overlap?
Both high availability and disaster recovery is aimed at business continuity and rely on redundancies. They both rely on continuous asset monitoring and a robust asset management strategy. Both processes can leverage asset management solutions such as InvGate Asset Management to send alerts in case of failures and manage risks associated with the components of different services.
Both processes are about mitigating risks to the business processes and the systems used for one may even be used by another. For example, the redundant servers or networking devices used for high availability can be part of the disaster recovery plan.
Frequently asked questions
What is high availability and how does it work?
High availability is the availability of a system to work without downtime for a long time. High availability systems are designed with multiple redundancies and eliminate single points of failure; even if one or more components of the system failed, the system as a whole can continue to function.
What are the nines that are referred to when discussing high availability?
They refer to the availability percentage, or the percent of the time for which a system is guaranteed to be available. For example, a system that guarantees 99.9%(8.77 hours of downtime per year) availability is referred to as three nines, and a system that guarantees 99.99%(4.38 hours per year) availability is referred to as four nines.
What is the difference between high availability and failover?
Failover is a mechanism used to implement a high availability system. It means that two or more systems may be running the same services and if one of them fails, the client simply gets connected to the other system and there’s no interruption of the service.

