O Gerenciamento de Incidentes Críticos, ou Major Incident Management (MIM) concentra-se em incidentes que têm um impacto em toda a empresa e exigem uma resposta imediata e coordenada. Esses incidentes colocam em risco os serviços essenciais, criam uma pressão urgente para restaurar as operações e podem afetar rapidamente a receita, a conformidade ou a reputação se forem prolongados.
Nem todo ticket de alta prioridade se qualifica como um incidente crítico. Um incidente de alta prioridade pode ser urgente para uma equipe ou um usuário. Um incidente crítico vai além: ele interrompe os serviços principais, afeta muitos usuários ou clientes, aumenta rapidamente e exige visibilidade da liderança e coordenação entre as equipes para recuperar o controle.
Neste artigo, explicaremos como o Gerenciamento de Incidentes Críticos funciona na prática, quando acioná-lo e como usar as ferramentas de ITSM para ajudar as equipes a responder mais rapidamente quando o impacto for grande demais para ser tratado como um negócio normal.
O que torna um incidente "crítico"?
Um incidente crítico é definido pelo impacto e pela urgência, não apenas pela prioridade. No momento em que um incidente ameaça as principais operações de negócios, ele deixa de ser tratado como trabalho de rotina e exige um nível diferente de resposta.
Use a checklist a seguir para decidir quando passar do Gerenciamento de Incidentes normal e acionar o Gerenciamento de Incidentes Críticos.
Um incidente é considerado critico quando uma ou mais dessas condições se aplicam:
- Amplo impacto: o problema afeta um grande número de usuários, clientes ou locais ao mesmo tempo, em vez de uma única equipe ou indivíduo.
- Serviços críticos envolvidos: os principais sistemas, como e-mail, autenticação, ERP, plataformas voltadas para o cliente ou serviços de pagamento, estão indisponíveis ou severamente degradados.
- Alta urgência para restaurar o serviço: os atrasos aumentam rapidamente o risco comercial. As soluções alternativas são limitadas ou inexistentes, e os tempos normais de resposta não são aceitáveis.
- Risco comercial ou financeiro: o incidente bloqueia as atividades geradoras de receita, interrompe as operações ou expõe a organização a problemas contratuais impactando o Gerenciamento de Nível de Serviço.
- Impacto na reputação: clientes, parceiros ou o público estão cientes da interrupção ou é provável que o problema chegue até eles se não for resolvido rapidamente.
- Dependência de várias equipes: a resolução exige coordenação entre várias equipes, fornecedores ou níveis de suporte, geralmente sob pressão de tempo.
Se vários desses critérios forem atendidos, o incidente deve ser tratado como crítico, mesmo que a causa principal ainda não esteja clara.
Exemplos típicos de incidentes críticos
- Uma interrupção do serviço de e-mail ou de identidade em toda a empresa que impeça os funcionários de trabalhar.
- Uma falha no sistema de produção que afeta os clientes durante o horário comercial.
- Uma interrupção de rede que afeta vários locais ou regiões.
- Um incidente de segurança que força sistemas críticos a ficarem off-line.
- Uma implementação com falha que interrompe um aplicativo comercial essencial.
O principal sinal é simples: quando o impacto vai além de uma única equipe e o tempo se torna um risco comercial, você não está mais lidando com um incidente padrão de alta prioridade.
Funções e responsabilidades durante um incidente crítico
Um processo bem-sucedido de Gerenciamento de Incidentes Críticos depende de funções claramente definidas. Todos os envolvidos precisam saber o que se espera deles, especialmente quando o tempo é crítico e a pressão é grande.
Veja a seguir as principais funções e responsabilidades normalmente envolvidas no Gerenciamento de Incidentes Críticos de TI:
- Gerente de incidentes críticos - Lidera o esforço de resposta, coordena as equipes e atua como ponto central de contato.
- Equipes de suporte de TI - Trabalham para diagnosticar e resolver o problema, com base em sua área de especialização (infraestrutura, rede, aplicativos etc.).
- Central de serviços - Registra o incidente, comunica-se com os usuários finais e faz o escalonamento conforme necessário.
- Líder de comunicações - Garante atualizações consistentes e oportunas para todas as partes interessadas, incluindo líderes de negócios, clientes e equipes internas.
- Gerente de mudanças (quando aplicável) - Coordena todas as mudanças emergenciais que precisam ser implementadas para resolver o problema.
- Partes interessadas do negócio - Fornecem o contexto do negócio, avaliam o impacto e ajudam a priorizar os esforços se houver riscos concorrentes.
Um processo de Gerenciamento de Incidentes Críticos que você pode seguir
Um processo sólido de Gerenciamento de Incidentes Críticos precisa ser rápido, estruturado e claro. Em situações de alta pressão, improvisar não é uma opção, todos precisam saber exatamente o que fazer e quando. Aqui estão as cinco etapas essenciais.
Etapa 1: detectar e classificar o incidente
A detecção geralmente vem de ferramentas de monitoramento, alertas ou relatórios de usuários. A classificação é o verdadeiro ponto de decisão.
Nessa etapa, as equipes avaliam:
- Serviços afetados.
- Número de usuários ou clientes afetados.
- Urgência e exposição comercial.
- Risco potencial à reputação ou à conformidade.
O objetivo é decidir se o incidente atende aos critérios de incidente crítico, e não confirmar a causa principal.
A comunicação antecipada faz parte dessa primeira etapa. Quando os usuários não têm informações, eles abrem tickets duplicados, fazem escalonamentos por meio de canais informais ou tentam soluções alternativas arriscadas, o que retarda a recuperação. Até mesmo atualizações parciais ajudam a definir as expectativas, confirmando que um incidente está em andamento, esclarecendo quais serviços foram afetados ou estão sendo investigados e informando que as equipes estão trabalhando ativamente na contenção ou restauração.
Etapa 2: coordenar
Uma vez classificado, o incidente deve ser escalado para as equipes certas, incluindo especialistas técnicos, partes interessadas do negócio e a central de serviços. De acordo com a estrutura da ITIL, essa etapa deve seguir um caminho de escalonamento predefinido.
Os principais elementos dessa etapa incluem:
- Designar um gerente de incidentes críticos.
- Envolvimento das equipes técnicas e das partes interessadas do negócio.
- Abrir canais de comunicação ao vivo.
- Estabelecer uma autoridade de decisão clara.
O gerente de incidentes críticos coordena o trabalho e a comunicação. Ele não soluciona problemas diretamente, mas mantém as equipes alinhadas e concentradas nas prioridades compartilhadas.
Etapa 3: responder e conter o impacto
O objetivo aqui é estabilizar a situação e limitar os danos adicionais, não consertar o problema subjacente.
As ações típicas de contenção incluem:
- Isolamento dos sistemas ou componentes afetados.
- Desativar integrações ou recursos com problemas.
- Reversão de alterações recentes.
- Mudança para backups ou ambientes de failover.
Essas ações podem ser temporárias. Seu objetivo é estabilizar os serviços e evitar que o incidente aumente enquanto a investigação continua.
Atualizações claras durante essa fase ajudam a reduzir a tensão e a manter as equipes alinhadas com o objetivo imediato: interromper o impacto futuro.
Etapa 4: resolver e recuperar
Com o incidente contido, as equipes podem trabalhar para obter uma resolução permanente.
Essa fase geralmente envolve:
- Identificar e corrigir a causa raiz.
- Restaurar a operação normal dos serviços.
- Validar o desempenho, o acesso e as dependências.
- Confirmar a recuperação com as partes interessadas afetadas.
A documentação também ocorre aqui, capturando cronogramas, ações e decisões enquanto os detalhes ainda estão frescos.
Etapa 5: revisar e melhorar
Quando tudo estiver pronto e funcionando, as equipes realizarão uma revisão pós-incidente. O objetivo é analisar o que deu errado, o que deu certo e o que pode ser feito melhor da próxima vez.
Crie um espaço seguro. As revisões não devem ser sobre culpa, elas devem se concentrar nos fatos, nas causas principais e nas oportunidades de melhoria. Use-as para refinar as funções e responsabilidades, os manuais e os protocolos de comunicação do Gerenciamento de Incidentes Críticos.
Modelos de comunicação que você pode reutilizar
Uma comunicação clara e consistente reduz a incerteza e mantém os usuários alinhados com a resposta. Esses modelos foram criados para serem breves, factuais e fáceis de adaptar durante um incidente crítico.
No momento, estamos investigando um incidente que afeta [serviço/sistema].
Alguns usuários podem sofrer [breve impacto].
Nossas equipes estão trabalhando ativamente para conter o problema.
Compartilharemos outra atualização até [hora] ou antes, se houver alguma mudança.
O incidente que afeta [serviço/sistema] ainda está em andamento.
O impacto permanece limitado a [usuários/áreas], e nenhum serviço adicional foi afetado no momento.
As equipes continuam trabalhando na contenção e recuperação.
A próxima atualização será compartilhada até [hora].
O incidente que afetou [serviço/sistema] foi resolvido.
Os serviços foram restaurados em [hora], e a operação normal foi retomada.
Estamos analisando o incidente para identificar ações de acompanhamento e evitar a recorrência.
Obrigado por sua paciência.
Como gerenciar os principais incidentes com o InvGate Service Management
O InvGate Service Management apoia o Gerenciamento de Incidentes Críticos, dando estrutura às equipes sem atrasá-las. A ideia é orientar a resposta através da automação do fluxo de trabalho, manter a visibilidade enquanto o incidente está ativo e capturar tudo o que é necessário para revisão posterior com análises e relatórios.
Veja como ele ajuda a sua equipe a manter o controle quando é mais importante:
1. Criando um incidente crítico no InvGate Service Management
No InvGate Service Management, um incidente crítico não é um escalonamento de um incidente existente. É um tipo de solicitação separado, criado explicitamente para gerenciar interrupções de alto impacto e generalizadas.
Somente os técnicos (agentes, gerentes e administradores) poderão criar incidentes críticos. O acesso pode ser ainda mais restrito a um determinado grupo de agentes usando regras de visibilidade. Os usuários finais são excluídos porque não têm visibilidade ou autoridade para determinar se uma interrupção se qualifica como um incidente crítico.
Tenha em mente:
- Um incidente padrão não pode ser convertido em um incidente crítico.
- Um incidente crítico deve ser criado como uma nova solicitação desde o início.
- Os incidentes existentes podem ser relacionados posteriormente ao incidente crítico.
Os incidentes críticos funcionam como uma camada de coordenação para eventos de massa. Uma vez criados, você pode vincular várias solicitações de incidentes ao incidente crítico, centralizando a comunicação, o rastreamento e a resolução.
Essa abordagem permite que as equipes:
- Gerenciem a interrupção mais ampla em um único local.
- Mantenham os incidentes individuais visíveis para os usuários afetados.
- Evitam a repetição das mesmas atualizações ou etapas de resolução.
Quando o incidente crítico é resolvido, a solução pode ser propagada automaticamente para todos os incidentes relacionados, aplicando o mesmo comentário de resolução e movendo-os para a confirmação do cliente.
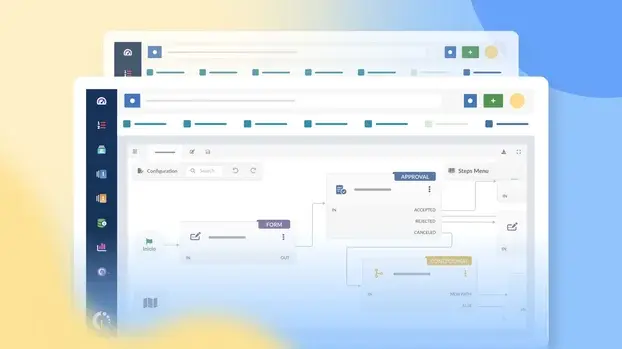
2. Criação de um fluxo de trabalho para incidentes críticos

Um fluxo de trabalho dedicado garante que os incidentes críticos sigam um caminho controlado, em vez de serem tratados como tickets padrão.
Usando o criador de fluxo de trabalho sem código, você pode definir como os incidentes críticos passam por estágios, funções e ações depois de criados.
Para um fluxo de trabalho típico de incidente crítico, você pode incluir:
- Um formulário inicial estruturado que captura o impacto, os serviços afetados e a urgência.
- Uma etapa condicional para validar o risco e o impacto.
- Aprovação opcional para confirmação de escalonamento.
- Tarefas obrigatórias para coordenação, contenção e resolução.
- Ações automatizadas, como anúncios, notificações ou reatribuições.
3. Recursos de IA para o Gerenciamento de Incidentes Críticos
O InvGate Service Management aplica inteligência artificial para ajudar as equipes a detectar incidentes críticos mais cedo e se comunicar de forma mais eficaz durante eventos críticos.
Detecção de incidentes críticos com IA
Os principais incidentes geralmente surgem de vários relatórios relacionados. A IA analisa continuamente os incidentes recebidos para identificar padrões que sugerem um problema mais amplo.
Quando um possível incidente crítico é detectado:
- Os gerentes de help desk recebem uma notificação do sistema e um e-mail.
- O incidente crítico sugerido inclui o raciocínio fornecido pela IA.
- Os gerentes podem criar o incidente principal com dados pré-preenchidos e solicitações vinculadas.
Para ativar essa funcionalidade, vá para Configurações → AI Hub → Detecção proativa e ative a detecção de incidentes críticos.

Análise preditiva de risco e impacto
A IA também oferece suporte à classificação, sugerindo níveis de risco e impacto com base em dados históricos de casos semelhantes. Isso ajuda as equipes a avaliar a exposição dos negócios com mais rapidez e a aplicar critérios consistentes durante o escalonamento.
Sugestões de anúncios gerados por IA
A comunicação é outro ponto de falha comum durante incidentes importantes. O InvGate Service Management aborda isso com sugestões de anúncios automáticos.
Quando um incidente crítico é criado ou atualizado, o sistema sugere e redige um anúncio. Os agentes e administradores podem revisar, editar e publicá-los imediatamente, para manter os usuários informados e evitar uma enxurrada de tickets duplicados.
Para ativar esse recurso, vá para Configurações > AI Hub > Assistência ao agente e ative as Sugestões para anúncios associados a incidentes principais.
4. Revisão pós-incidente e melhoria contínua
Depois de resolver um incidente crítico, o foco muda para aprender e evitar futuras interrupções. O InvGate Service Management fornece ferramentas para tornar as atividades pós-incidente estruturadas e acionáveis.
- Análises e relatórios: use painéis e relatórios integrados para analisar cronogramas, padrões de escalonamento, serviços afetados e desempenho da equipe. Esses insights ajudam a identificar gargalos e a medir a eficácia da resposta.
- Gerenciamento de Problemas: vincule o incidente crítico aos registros de problemas para investigar as causas básicas, rastrear problemas recorrentes e implementar correções de longo prazo. Isso garante que a mesma interrupção não se repita.
- Documentar os aprendizados pós-incidente: registre as principais decisões, a eficácia da comunicação e as lições aprendidas em um formato estruturado. Armazene essa documentação para auditorias, referência futura e aprimoramento contínuo do processo.
É mais fácil gerenciar incidentes críticos quando sua plataforma centraliza a detecção, o escalonamento e a comunicação em um único local. Quer ver mais? Solicite uma demo gratuita ou inicie uma avaliação gratuita do InvGate Service Management hoje mesmo e veja como a sua equipe pode responder mais rapidamente, reduzir o ruído e manter os usuários informados durante as interrupções críticas.